Word2vec Code 阅读笔记
2014-07-29 by Leonvia: liustrive.com
参数:
hs
negative
int binary = 0, cbow = 0, debug_mode = 2, window = 5, min_count = 5, num_threads = 1, min_reduce = 1; // window是训练时前后文长度随机数的边界,其它参数看名字
layer1_size // 向量维度
结构:
基本词结构体
struct vocab_word {
long long cn; // 词频数
int *point; // root 到该节点的路径,存的是路径节点索引
char *word, // 词串
*code, // Huffman编码
codelen; // Huffman码长度
};
全局变量:
struct vocab_word *vocab; // 词表
值得注意的是词表的内存是1000为单位递增扩大的,相关代码:
if (vocab_size + 2 >= vocab_max_size) {
vocab_max_size += 1000;
vocab = (struct vocab_word *)realloc(vocab, vocab_max_size * sizeof(struct vocab_word));
}
int *vocab_hash; // 词hash码对应词下标的数组
vocab_hash[hashcode] –> index
需要注意的是word2vec采用的是标准hash table存放方式,hash码重复后挨着放
取的时候根据拿出index找到词表里真正单词,跟比一下
syn0
就是词向量的大矩阵,第i行表示vocab中下标为i的词
syn1
用hs算法时用到的辅助矩阵,即文章中的Wx
syn1neg
negative sampling算法时用到的辅助矩阵
Next_random
作者自己生成的随机数,线程里面初始化就是:
unsigned long long next_random = (long long)id;
更新用的:
next_random = next_random * (unsigned long long)25214903917 + 11;
伪随机伪到家了=_=
expTable
直接用一个数组记录指数值,要用的时候直接查近似值,不用算,其初始化代码如下:
expTable = (real *)malloc((EXP_TABLE_SIZE + 1) * sizeof(real));
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP);
expTable[i] = expTable[i] / (expTable[i] + 1); // Precompute f(x) = x / (x + 1)
}
vocab_size
词表大小
函数:
void InitNet()
主要承担初始化、开内存、建Huffman树的任务,为syn0,syn1(采用HS时),syn1neg(采用negative时)开内存,其中syn0用-0.005~0.005之间的数随机初始化
void CreateBinaryTree()
创建Huffman树,以词频为权重,于是词频越高的词Huffman code越短
基本流程与Huffman建树算法一致,但是代码很优雅
void TrainModelThread(void id)
SubSample 相关代码

一定概率扔掉高频词,词频越高discard概率越大。
代码
neu1 隐层矩阵 neu1[i]为隐层向量,
CBOW
b = next_random % window;
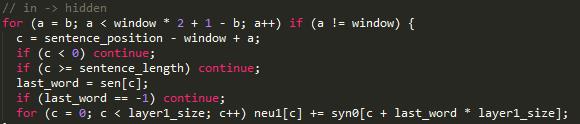
HS
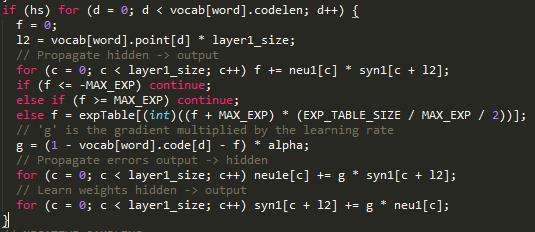
其中,f是 \(σ(neu1^T ×syn1)\) ,l2是父节点索引
交叉熵L为:
其中
于是有:
求对syn1的偏导:
对neu1求偏导:
所以g是梯度乘以学习速率中的公因子。
Negative Sampling 代码
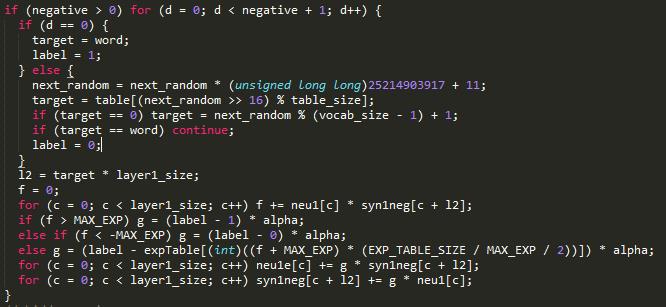
抽取的负样本label为0,可以看做HS中的一层 于是有
隐藏层到输入层:
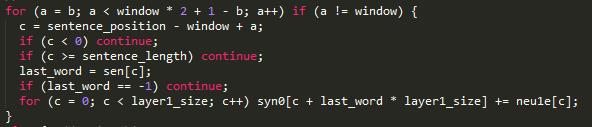
前面用的输入层向量相加得到隐层向量,于是对词向量的更新可以直接用梯度neu1e[c]
Linguistic Regularities in Continuous Space Word Representations 阅读笔记
via: liustrive.com
这篇文章主要就是介绍词向量支持基本代数运算的特性,并利用这一特性将之应用到SemEval 2012 Task 来衡量。
背景:
SemEval 2012 task
Recurrent Neural Network Model
RNNLM模型由输入层、带有循环连接以及对应权重矩阵的隐藏层、输出层构成,如下图:
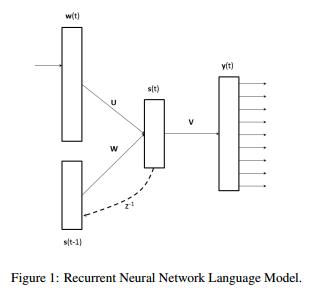
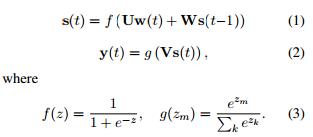
训练产出中词向量保存在参数矩阵U中,模型训练采用后向传播的最大化对数似然函数方法。
实验部分
测试集
Syntactic Test Set
词向量的语法规则测试集如下图Table1
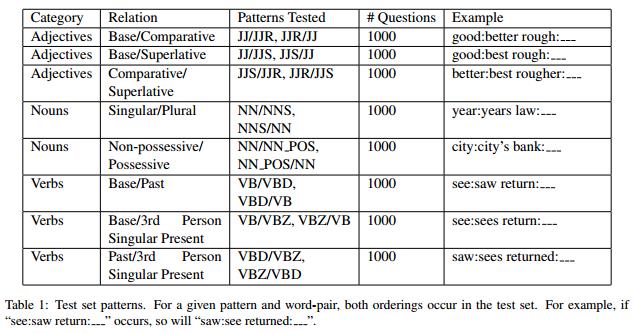
作者采用Penn Treebank POS tags对报纸新闻文本做标记,选取词频最高的前100组(JJ/JJR ...
read moreDistributed Representations of Words and Phrases and their Compositionality 阅读笔记
via: liustrive.com
文章提出了一些对Skp-gram模型的扩展,提出一种NCE(Noise Contrastive Estimation )方法用以代替上文hierarchical softmax方法,从而获得更高的效率和对高频词的更好的词向量结果。 文中提到词向量表示的一大弊端是它们无法表示一些词组成的常用短语,这短语不是字面上把其组成词连接起来的意义,于是提出扩展,将基于词的模型变成基于短语的模型,扩展的原理是先抓出这些短语,然后把这些短语作为整体的“词”加入训练集,然后使用上文实验部分中提到的方法,利用词向量代数运算验证准确性。
The Skip-gram Model
上文介绍过skip-gram模型的结构,给定一句由训练词{w1,w2,w3…wT},其目标是最大化平均对数概率,c为目标词的前后上下文长度
Efficient Estimation of Word Representations in Vector Space 阅读笔记
via: liustrive.com
背景
现有模型,比如前文Bengio的采用非线性激活函数tanh的神经网络模型,虽然准确度上有优势,但是算法的复杂度较高,无法训练更大的数据集,比如特征向量维度为50-100情况下训练超过几百兆个的语料。
目标
提出一种模型使其能够训练百万级词表下数十亿词量的训练集,并产出优质词特征向量。
Model Architectures
Feedforward Neural Net Language Model (NNLM)
此即前文所述前向神经网络语言模型,采用四层神经网络(原文讲实际是三层神经网络) 输入层、投影层、隐藏层、输出层 每个训练样本的计算复杂度为:
A Neural Probabilistic Language Model 入门笔记
Via: liusrive.com
目标:
learn the joint probability function of sequences of words in a language
学习某种语言中单词序列的联合概率函数 即根据训练集按照一定的算法建立一种数学模型,使之能够计算出某个句子在该模型下出现的概率,以及根据前N-1个词决定第N个词出现的概率。
注:见背景知识:语言模型及n-gram 模型
该目标面临的主要困难:
Curse of dimensionality 维数灾难
具体表现为:
a word sequence on which the model will be tested is likely to be different from all the word sequences ...