Word2vec Code 阅读笔记
2014-07-29 by Leonvia: liustrive.com
参数:
hs
negative
int binary = 0, cbow = 0, debug_mode = 2, window = 5, min_count = 5, num_threads = 1, min_reduce = 1; // window是训练时前后文长度随机数的边界,其它参数看名字
layer1_size // 向量维度
结构:
基本词结构体
struct vocab_word {
long long cn; // 词频数
int *point; // root 到该节点的路径,存的是路径节点索引
char *word, // 词串
*code, // Huffman编码
codelen; // Huffman码长度
};
全局变量:
struct vocab_word *vocab; // 词表
值得注意的是词表的内存是1000为单位递增扩大的,相关代码:
if (vocab_size + 2 >= vocab_max_size) {
vocab_max_size += 1000;
vocab = (struct vocab_word *)realloc(vocab, vocab_max_size * sizeof(struct vocab_word));
}
int *vocab_hash; // 词hash码对应词下标的数组
vocab_hash[hashcode] –> index
需要注意的是word2vec采用的是标准hash table存放方式,hash码重复后挨着放
取的时候根据拿出index找到词表里真正单词,跟比一下
syn0
就是词向量的大矩阵,第i行表示vocab中下标为i的词
syn1
用hs算法时用到的辅助矩阵,即文章中的Wx
syn1neg
negative sampling算法时用到的辅助矩阵
Next_random
作者自己生成的随机数,线程里面初始化就是:
unsigned long long next_random = (long long)id;
更新用的:
next_random = next_random * (unsigned long long)25214903917 + 11;
伪随机伪到家了=_=
expTable
直接用一个数组记录指数值,要用的时候直接查近似值,不用算,其初始化代码如下:
expTable = (real *)malloc((EXP_TABLE_SIZE + 1) * sizeof(real));
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP);
expTable[i] = expTable[i] / (expTable[i] + 1); // Precompute f(x) = x / (x + 1)
}
vocab_size
词表大小
函数:
void InitNet()
主要承担初始化、开内存、建Huffman树的任务,为syn0,syn1(采用HS时),syn1neg(采用negative时)开内存,其中syn0用-0.005~0.005之间的数随机初始化
void CreateBinaryTree()
创建Huffman树,以词频为权重,于是词频越高的词Huffman code越短
基本流程与Huffman建树算法一致,但是代码很优雅
void TrainModelThread(void id)
SubSample 相关代码

一定概率扔掉高频词,词频越高discard概率越大。
代码
neu1 隐层矩阵 neu1[i]为隐层向量,
CBOW
b = next_random % window;
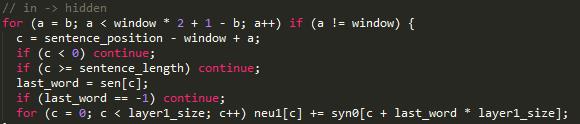
HS
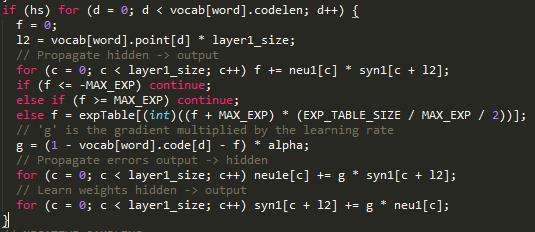
其中,f是 \(σ(neu1^T ×syn1)\) ,l2是父节点索引
交叉熵L为:
其中
于是有:
求对syn1的偏导:
对neu1求偏导:
所以g是梯度乘以学习速率中的公因子。
Negative Sampling 代码
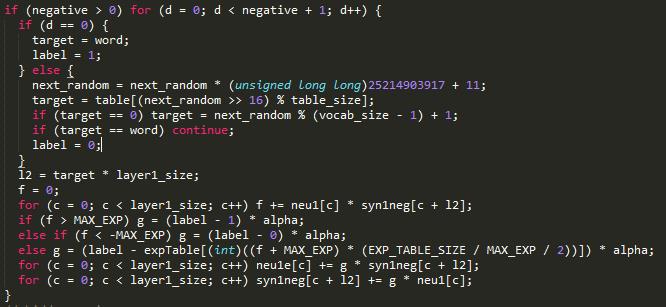
抽取的负样本label为0,可以看做HS中的一层 于是有
隐藏层到输入层:
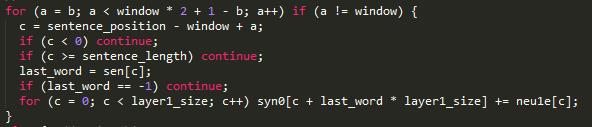
前面用的输入层向量相加得到隐层向量,于是对词向量的更新可以直接用梯度neu1e[c]