Linguistic Regularities in Continuous Space Word Representations 阅读笔记
2014-07-27 by Leonvia: liustrive.com
这篇文章主要就是介绍词向量支持基本代数运算的特性,并利用这一特性将之应用到SemEval 2012 Task 来衡量。
背景:
SemEval 2012 task
Recurrent Neural Network Model
RNNLM模型由输入层、带有循环连接以及对应权重矩阵的隐藏层、输出层构成,如下图:
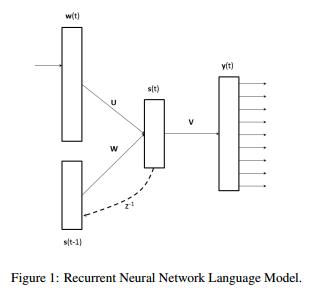
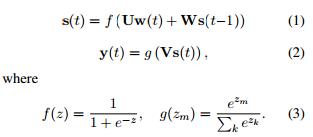
训练产出中词向量保存在参数矩阵U中,模型训练采用后向传播的最大化对数似然函数方法。
实验部分
测试集
Syntactic Test Set
词向量的语法规则测试集如下图Table1
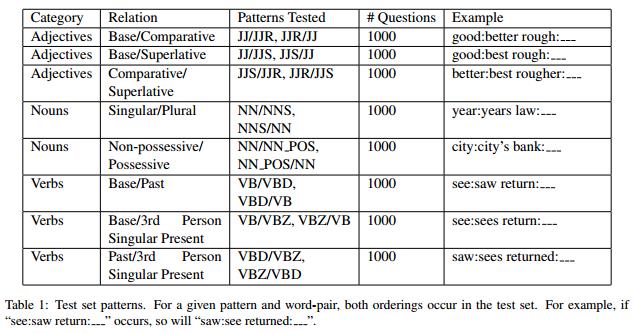
作者采用Penn Treebank POS tags对报纸新闻文本做标记,选取词频最高的前100组(JJ/JJR,NN/NNS ,NN/NN_POS,VB/VBD, VBD/VBZ)这样的组合作为测试集,总大小8000组。
Semantic Test Set 词向量的语义测试集用的是SemEval-2012 Task 2,来测试RNNLM训练出的词向量所包含的语义规则.
The Vector Offset Method
这部分主要就是介绍词向量之间的空间规则,比如之前的实验测试了向量:
实验验证结果
作者使用上文RNNLM模型分别生成了80、320、640、1600维的词向量,其数据集是320M的Broadcase News,词表大小为82k,测试采用上文的测试方式,主要对比对象时LSA得到结果如图Table2

可以发现以语法规则的精确性衡量,RNNLM模型词向量精确性上具有优势,而后作者还将RNNLM与其它已知的模型做对比,采用这些模型使用的测试集:6632个问句,36k的词表大小,37M大小的词量,结果如图Table3:

发现Hierarchical Log-Bilinear Model几乎与RNNLM提供了一样的精确度,由于输入集是37M的词量,这可能说明前者有更好的鲁棒性。
之后作者对语义规则做了类似的测试,上文提到的SemEval-2012 Task 2,使用task中Spearman’s rank correlation coefficient ρ 和 MaxDiff accuracy两个用例,有79组词性关系,其中10组用于训练,69组词组关系作为测试集,实验得到结果如图Table4:

可以发现虽然RNN模型并未特意为这个任务采取训练或调整,相比其他模型仍具有最好的效果,同时观察到其准确率随着词向量维度增加而增长。